JavaScript: Updating DOM during a long-running computation
When running a lengthy computation, it's considered good practice to provide an indication of progress to the user. This can be surprisingly difficult in client-side JavaScript, even with modern ECMAScript features like Promises and async/await. The difficulty arises with continuously-running computations. Such computations block the event loop and typically prevent the browser from updating the DOM. Which means, any progress indicators updated in the DOM will not be visible until the computation has completed. And that kind of defeats the purpose of progress indicators.
One way to solve this problem is to move computationally-intensive code into a web worker, which will run in the background and not block the event loop. And that's a good way to do it most of the time. However, web workers do have some limitations. Transferring large amounts of data from a web worker to the main thread is not straightforward, and might require copying it, effectively doubling the memory usage of a large data set. For example, I found myself facing this issue when processing a large time-series data set that needed to be passed to a visualization library in the main thread.
So here's another way to do it. The approach is a helper function, which I'll call doUntil, which handles periodically yielding execution to allow the DOM to update. So rather than using, say, a for loop to iterate over the data, the body of that loop is encapsulated in a function and passed to the helper function. In addition to the loop body, the helper function takes two additional boolean-valued functions: one that returns true when it is time to temporarily yield execution, and one that returns true when the computation has completed. Here's an example that uses doUntil to calculate the primes between 2 and 1000000 (full code).
function findPrimesNonBlocking() {
// Initialize loop variable and list of primes
let n = 2;
let primes = [];
// Yield every 1000 iterations and stop after 1000000
const stopCondition = () => n == 1000000;
const yieldCondition = () => n % 10000 == 0;
// Build the loop body to be passed to doUntil()
const loop = () => {
// Determine if n is prime
if (isPrime(n, primes)) {
primes.push(n);
}
// Increment n
n += 1;
// Update DOM if we're about to yield
if (yieldCondition()) {
document.body.textContent =
`Found ${primes.length} primes between 2 and ${n}`;
}
};
// Execute
doUntil(loop, stopCondition, yieldCondition);
}
In the above code, the loop function encapsulates a single iteration of the computation, namely testing a single number for primality. The yieldCondition function returns true every 10000 iterations, providing feedback frequently, but not so frequently that repeated DOM updates slow the browser. The stopCondition function stops execution after the loop variable n reaches 1000000. In this case, the code indicates status by reporting the number of primes found so far, but the entire array primes is available to the main thread at all times, without the need to copy it. It's also worth noting that doUntil returns a Promise, so it can be wrapped in async/await if desired, or a then clause can be added.
Here's the code for doUntil. It creates an outerLoop function that repeatedly calls the provided loop function, checking for yield and stop conditions between each iteration. When it is time to yield, setTimeout is used to queue up the next iteration in the event loop, providing a chance for the DOM to update. Because loop and even outerLoop are called multiple times throughout the computation, the computation state (in this case n and primes) has to be stored elsewhere, namely in the scope of the calling function (findPrimesNonBlocking in the example). The loop function is also defined in the scope of the calling function, giving it access to the state variables.
function doUntil(loop, stopCondition, yieldCondition) {
// Wrap function in promise so it can run asynchronously
return new Promise((resolve, reject) => {
// Build outerLoop function to pass to setTimeout
let outerLoop = function () {
while (true) {
// Execute a single inner loop iteration
loop();
if (stopCondition()) {
// Resolve promise, exit outer loop,
// and do not re-enter
resolve();
break;
} else if (yieldCondition()) {
// Exit outer loop and queue up next
// outer loop iteration for next event loop cycle
setTimeout(outerLoop, 0);
break;
}
// Continue to next inner loop iteration
// without yielding
}
};
// Start the first iteration of outer loop,
// unless the stop condition is met
if (!stopCondition()) {
setTimeout(outerLoop, 0);
}
});
}
So if you've got a lengthy computation in the main JavaScript thread and you want to update a progress indicator in the DOM, this is one way to do it.
One more time, with feeling! Toward reproducible computational science
My scientific education was committed at the hands of physicists. And though I've moved on from academic physics, I've taken bits of it with me. In MIT's infamous Junior Lab, all students were assigned lab notebooks, which we used to document our progress reproducing significant experiments in modern physics. It was hard. I made a lot of mistakes. But my professors told me that instead of erasing the mistakes, I should strike them out with a single line, leaving them forever legible. Because mistakes are part of science (or any other human endeavor). So when mistakes happen, the important thing is to understand and document them. I still have my notebooks, and I can look back and see exactly what I did in those experiments, mistakes and all. And that's the point. You can go back and recreate exactly what I did, avoid the mistakes I caught, and identify any I might have missed. Ideally, science is supposed to be reproducible. In current practice though, most research is never replicated, and when it is, the results are very often not reproducible. I'm particularly concerned with reproducibility in the emerging field of computational social science, which relies so heavily on software. Because as everyone knows, software kind of sucks. So here are a few of the tricks I've been using as a researcher to try to make my work a little more reproducible.
Databases
When I'm doing anything complicated with large amounts of data, I often like to use a database. Databases are great at searching and sorting through large amounts of data quickly and making the best use of the available hardware, far better than anything I could write myself in most cases. They've also been thoroughly tested. It used to be that relational databases were the only option. Relational databases allow you to link different types of data using a query language (usually SQL) to create complicated queries. A query might translate to something like "show me every movie in which Kevin Bacon does not appear, but an actor who has appeared in another movie with Kevin Bacon does." A lot of the work is done by the database. What's more, most relational databases guarantee a set of properties called ACID. Generally speaking, ACID means that even if you're accessing a database from several threads or processes, it won't (for example) change the data halfway through a query.
In recent years, NoSQL databases (key-value stores, document stores, etc.) have become a popular alternative to relational databases. They're simple and fast, so it's easy to see why they're popular. But their simplicity means your code needs to do more of the work, and that means you have more to test, debug, and document. And the performance is usually achieved by dropping some of the ACID requirements, meaning that in some cases data might change in the middle of a calculation or just plain disappear. That's fine if you're writing a search engine for cat gifs, but not if you're trying to do verifiably correct and reproducible calculations. And the more data you're working with, the more likely one of these problems is to pop up. So when I use a database for scientific work, I currently prefer to stick with relational databases.
Unit tests
Some bugs are harder to find than others. If you have a syntax error, your compiler or interpreter will tell you right away. But if you have a logic error, like a plus where you meant to put a minus, your program will run fine, it'll just give you the wrong output. This is particularly dangerous in research, where by definition you don't know what the output should be. So how do you check for these kinds of errors? One option is to look at the output and see if it makes sense. But this approach opens the door to confirmation bias. You'll only catch the bugs that make the output look less like what you expect. Any bugs that make the output look more like what you expect to see will go unnoticed.
So what's a researcher to do? This is where unit tests come in. Unit tests are common in the world of software engineering, but they haven't caught on in scientific computing yet. The idea is to divide your code into small chunks, and test each part individually. The tests are programs themselves, so they're easy to re-run if you change your code. To do this in a research context, I like to compare the output of each chunk to a hand calculation. I start by creating a data set small enough to analyze by hand, but large enough to capture important features, and writing it down in my lab notebook. Then for each stage of my processing pipeline, I calculate what the input and output will be for that data set by hand and write that down in my lab notebook. Then I write unit tests to verify that my code gives the right output for the test data. It almost always doesn't the first time I run it, but more often than not it's a problem with my hand calculation. You can check out an example here. A nice side effect of doing unit tests is that it gives you confidence in your code, which means you can devote all of your attention to interpreting results, rather than second guessing your code.
Version control
Version control tools like git are becoming more common in scientific computing. On top of making it easy to roll back changes that break your code, they also make it possible to keep track exactly what the code looked like when an analysis was run. That makes it possible to check out an old version of code and re-run an analysis exactly. Now that's how you reproducible! One caveat here: in order to keep an accurate record of the code that was run, you have to make sure all changes have been committed and that the revision id is recorded somewhere.
Logging

Finally, logging the process of analysis scripts makes it a lot easier to know exactly what your code did, especially years after the fact. In order to help match my results with the version of code that produced them, I wrote a small logging helper script that automatically opens a standard python log in a directory based on the experiment name, timestamp, and current git hash. It also makes it easy to create output files in that directory. Using a script like this makes it easy to know when a script was run, exactly what version of the code it used, and what happened during the script execution.
As for the specific logging messages, there are a few things I always try to include. First, I always have a message for when the script starts and completes successfully. I also wrap all of my scripts in a try/except block and log any unhandled exceptions. I also like to log progress, so that if the script crashes, I can know where to look for the error and where to restart it. Logging progress also makes it easier to estimate how long a script will take to finish.
Using all of these techniques has definitely made my code easier to follow and retrace, but there's still so much more that we can do to make research truly open and reproducible. Has anyone reading this tried anything similar? Or are there things I've left out? I'd love to hear what other people are up to along these lines.
ResourceListener: many endpoints, many requests
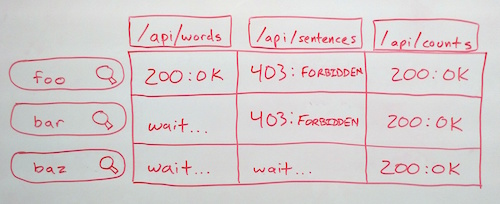
While building the new MediaMeter Dashboard tool, the team at the MIT Center for Civic Media faced an interesting design challenge: keeping track of multiple requests to each of multiple API endpoints and rendering views when the right data is ready. For more context, we designed the Dashboard as a front end for the Media Cloud API from Harvard's Berkman Center. We wanted users to be able to enter several searches and compare the results in many different ways (e.g. result count over time, word frequency, text snippets). What's more, we wanted the tool to be extensible, so it was easy to add new visualizations or accommodate new API endpoints. So we're creating a request for every search/endpoint combination, and each visualization could potentially depend on any combination of them. To make all these requests manageable, I augmented backbone.js's built-in events with a ResourceListener class.
ResourceListener is based on the EventAggregator pattern. A single object aggregates all events related to API requests. All of the different visualizations can then listen to that object for resource-related events, rather than listening to specific models and collections directly. To use the ResourceListener, you need to add a "resourceType" attribute when defining models or collections. Then, after creating the models, simply pass them to the ResourceListener's listen() method. Every time a request is made, the ResourceListener will fire a "request" event and pass the model or collection as a parameter. When the request completes, the ResourceListener will fire a "sync" event, again passing the model as an object. If your only interested in responses from a particular endpoint, you can instead listen to "sync:type" events, where "type" is the "resourceType" attribute of the model or collection. The ResourceListener also fires "resource:complete:type" events when all resources of a particular type are complete, and a "resource:allComplete" when all resources of all types have finished. By passing the ResourceListener object to your views, you can then listen for exactly the events you need, and render as soon as they're complete, without waiting for other requests.
ViewManager: Persistent Views in Single-Page Web Apps
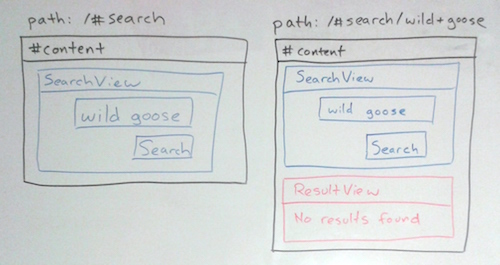
JavaScript frameworks like backbone.js make it easy to create web app content based on the path using Router and View objects. But what if you want some views, and their state, to persist across certain routes? That can be tricky, so I created a simple ViewManager class to take care of the hard parts.
For a concrete example, consider an application that shows a search form (SearchView) and displays the results (ResultView) when it's submitted. You might want to keep displaying the search form along with the results, in case the user wants to modify their search (this is exactly the case that inspired ViewManager while I was working on MediaMeter Dashboard). Following best practices for single-page apps, you put the search results under a different path from the blank search form to allow links directly to the results. But now it gets complicated. If the user gets to the results from the search page, the SearchView already exists, but if the user is coming from a link, the SearchView needs to be created. Same route, different behavior based on the previous route. One approach would be to remove and destroy all views and create them anew every time the route changes. But on top of potentially hindering performance, creating a new view every time destroys useful View state, for instance: whether components of the view are expanded or collapsed.
ViewManager makes it easy to persist views across routes by providing a factory to create views when needed, and a method to automatically hide/show views (similar to the d3.js general update pattern). The getView() factory method takes a View constructor as an argument and either returns the existing view of that class, or creates a new one. The client code doesn't need to keep track of which views already exist, just always call getView() and you don't have to worry about creating duplicates.
The showViews() function is the other half of ViewManager. This function takes a list of views to display, hides any existing views not in the list, and adds any new views that aren't already displayed. If one of the views is already displayed, it won't be recreated and all of the DOM elements will maintain their state. This functionality is also really helpful if you want to add a fade or slide transition when a view is shown or hidden, but don't want to trigger it on route changes.
A graceful end to Seltzer development
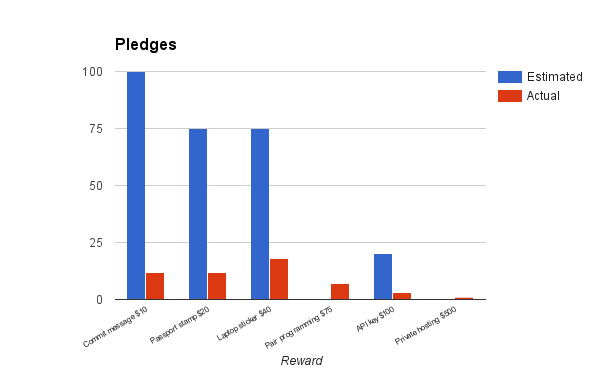
The Kickstarter I’ve been running for Seltzer (a tool for managing cooperatives) finished last night, at just shy of 1/3 of the funding goal. While the project wasn’t successfully funded, the crowdfunding campaign was far from a failure.
Over the past few weeks, I’ve learned an incredible amount about who is actually interested in Seltzer, and how much they’re able to participate. I received dozens of encouraging messages from organizers and administrators telling me how much they needed software like Seltzer. And I'm incredibly grateful to everyone who did pledge money to the project. I know many people stretched themselves to give generously. But, in the end, it wasn't enough to fund the project. Several people have told me I should have done an Indiegogo so I’d still get the money that was pledged, but here’s the secret: the campaign was as much about gauging interest as it was about raising money. The main goal of Seltzer has never been to create an application with a specific set of features, but to cultivate an open source community that could work together on an application that meets their common needs. No amount of money can buy that. Now I know that the time isn’t right, and I can apply myself more effectively elsewhere.
So what specifically did I learn? I had expected most of the support to come from people and organizations that were already using Seltzer or at least knew what it was, but I found just the opposite, which might mean that the existing version is actually good enough for everyone using it. I’d also expected many more small-dollar donations but was surprised to see that I got more $40 donations than $10 or $20. Data management isn’t sexy, so I realize now that those small dollar donations needed a more exciting reward to overcome the "sign into Kickstarter" activation energy.
I’d also expected more support from existing hackerspaces, both in the form of larger pledges and encouraging members to make smaller pledges. Members of a few spaces did take this on, but not as many as I’d planned on. The biggest challenge was establishing and maintaining contact. If I could do it again, I’d have started reaching out to hackerspaces months earlier and held regular calls to keep the momentum going. Volunteer organizations move slowly, and are easily distracted.
I’m a little sad that the campaign didn’t get funded, but it’s important to know when to end a project gracefully. So what does this mean for the future of Seltzer? Well, I won’t be developing a new version any time soon. Instead I’ll continue answering questions and reviewing bug-fixes, but no new features, on the existing version. Edit: And don't forget, you can still write your own modules to integrate with the existing code! I’ll also continue organizing people around cooperative software and linked data. If you want to be involved, join the cooperative software mailing list. I’ll also keep following exciting tech developments like JSON-LD. Who knows, maybe there will be a resurgence in interest for Seltzer later on, and I'd certainly consider another crowdfunding campaign, maybe over summer in some future year. In the meantime, it looks like I'll have four-day weekends for the rest of the this summer, so I should be able to relax a bit and catch up on reading and other side-projects.
Art, Code, and Asking

As a programmer, I know that code can be beautiful. As an artist, I know that code is not art. I don’t mean to say that code is in any way less, just different. And the difference is important, particularly when it comes to asking for support.
It’s a very exciting time for artists, as many turn to crowdfunding to support themselves. Either through single-shot funding campaigns, or ongoing patronage, artists are asking their fans for direct financial support, and fans are happy to give. The Boston-based musician Amanda Palmer has led the way, raising over a million dollars on Kickstarter to produce her most recent album. She reflects on the campaign in her book, The Art of Asking. In a passage that hit particularly close to home for me, she recounts a conversation with her mother, a programmer. As a teenager, Amanda had accused her mother of not being a “real artist” and years later, her mother told her:
You know, Amanda, it always bothered me. You can’t see my art, but… I’m one of the best artists I know. It’s just… nobody could ever see the beautiful things I made. Because you couldn’t hang them in a gallery.
Amanda came to recognize the unappreciated beauty of her mother’s work, and I have no doubt it was beautiful. But art is not just about beauty.
A few years ago, I was sitting in a client’s office in San Francisco, at a tiny desk overlooking the Highway 101 onramp, listening to music and writing code. The music was beautiful, but more than that, it showed me an entirely new perspective, that somehow felt deeply familiar. And in that moment, I felt a little more connected to humanity, and a little less alone. But I was sad to realize that my work would never help anyone else feel that way. I remembered a quote from Maya Angelou:
I've learned that people will forget what you said, people will forget what you did, but people will never forget how you made them feel.
Art catches and holds people’s attention by helping them feel new things. My work as a programmer, on the other hand, was forgettable. In fact, there’s a thing in software called the principle of least surprise: the better your code is, the less people even notice it exists. For a while, the thought of being unnoticed and forgettable left me with a sense of loss.
Relief came when I realized that although my code might never touch someone directly, it can (and has) helped artists who do. Just as the artist inspires the cancer researcher, the programmer empowers the artist. While the thought put an end to my mini existential crisis, some consequences remain, and that brings us back to asking for support.
Fans like Amanda Palmer’s give because they want to. They’re grateful for the gift of art, and they want to reciprocate. Emotion is a great motivator. But what about code? Software is complex, and beautiful, and important, but it doesn’t inspire the same emotion or generosity, because you never see the beauty. You can describe the types of things software will make possible, but that can seem overly abstract. I would like to think that crowdfunding can work for software as well as art. In fact, I’m currently running a campaign for software to manage makerspaces and other cooperatives. But how can programmers create the same connection with their users that artists create with their fans?
xsection.js | 30 Years in Data
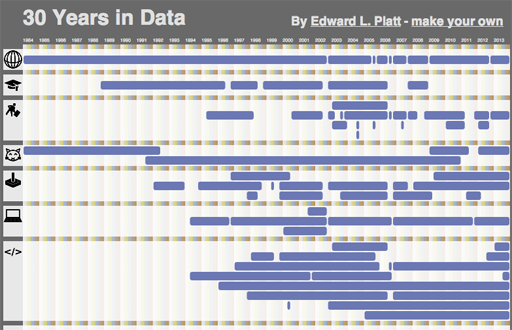
The Earth has, just today, completed revolving around the sun three times for each finger on a typical human hand since the day I was born. To commemorate the occasion, I made an interactive visualization of my life. I've open-sourced the code as xsection.js and you can create your own custom version by modifying the data.js file.
Laminar Flow Fountain

This year at Maker Faire Detroit, I helped Matt Oehrlein and the team from i3 Detroit with their laminar flow fountain. The fountain is composed of three laminar jets. Each jet shoots into a barrel containing the next jet, creating a ring. The individual jets are controlled by an Arduino which wirelessly communicates with a Makey-Makey connected to three brass candle holders. Touching two of the candle holders causes a jet to connect the corresponding two barrels.
Since the project was built in Detroit, and I'm living in Boston these days, I wasn't able to help with the fountain construction. Instead I helped create a "screensaver" demo to show the fountain off when there isn't any activity on the controller. I didn't have access to the electronics when I started because 1. they were in Detroit and 2. they weren't finished yet, so instead I wrote a simulator for the fountain in Processing and worked on it in Boston.
Since the team from i3 was using an Arduino to control the fountain, and the Arduino language is a subset of Processing, I was able to copy my demo code straight from the simulator and into the controller code. You can see the result in the video above, showing the demo running on the fountain with the simulator in the upper right corner.
I wish I could take credit for the fountain itself, because it turned out amazingly well (despite a lot of wind throughout the Faire). The demo was still a lot of fun to work on, and this project now has me thinking about more ways the Arduino/Processing combo can be used for remote collaborations.
Drupal Hooks Should Use PubSub
Drupal is an incredibly flexible piece of software, but that flexibility often comes at the price of slow performance. After several years working on Seltzer CRM, which I modeled after Drupal 6, I've realized that there is a simple way to get the same flexibility without as much of a hit to performance.
Drupal achieves its flexibility through modules and hooks. A Drupal module is simply a self-contained chunk of code that can be installed and enabled to provide a set of features, like a shopping cart, or comment moderation. A hook is a function in one module that changes the behavior of another module, like taking a form produced by one module, and altering its contents. Drupal's takes an implicit approach. If I have a module foo and I want it to alter forms produced by other modules, I implement the hook_form_alter() hook like so:
function foo_form_alter(&, &, ) { ... }
Whenever the form system creates a new form, it checks each module to see if hook_form_alter() is implemented, and if it is, passes the form data through that function. All my module needs to do is define the function. So what's the problem?
The performance problem is in plain sight. Every time a hook is called, every module needs to be checked for the existence of that function. The number of checks increases linearly with the number of modules, and in practice, most of those checks are unnecessary because any given hook will only be implemented by a small fraction of available modules. We can improve performance by switching to an explicit approach.
For our first try, let's invent a function called form_alter_register() that allows our module to explicitly register a callback:
form_alter_register('foo_form_alter');
function foo_form_alter(&, &, ) { ... }
Now, the form system can check each callback in the list rather than checking each module, which could speed things up quite a bit!
However, we're not quite at the same level of flexibility yet. Let's imagine that there's another module called "widget" and if its installed we want to be able to alter widgets as well. We do the following, right?
widget_alter_register('foo_form_alter');
function foo_widget_alter(&) { ... }
It works fine if the widget module is enabled, but what if the widget module is optional? Then widget_alter_register('foo_form_alter') won't be defined, and our code will crash! We could check whether the function exists before calling it, but that could get tedious. Better yet, we can use the same trick again, resulting in something like a publication-subscription approach.
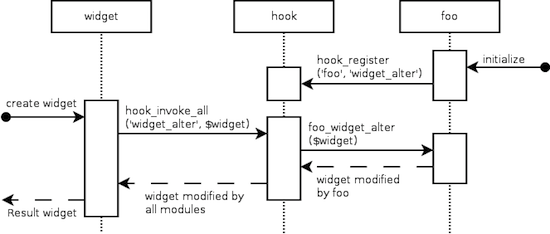
Specifically, we define two core functions, one that allows modules to register the hooks they implement, and one that calls all hooks of a given name:
function hook_register(, ) { ... }
function hook_invoke_all() { ... }
Then our code to implement the hook looks like this:
hook_register('foo', 'widget_alter');
function foo_widget_alter(&) { ... }
Now we have improved performance and the same level of flexibility. Some might argue that even calling hook_register() before each hook definition is tedious, and it may be. On the other hand, code is read more than it is written (as the adage goes) and this pattern explicitly identifies a hook as such, making it more readable, while Drupal's current pattern does not. So for improved performance and readability, the next time I'm writing a modular framework, I'm likely to use this pattern instead.
PS: Does anyone know if there is a proper design pattern name for either of these approaches?
Seltzer CRM
Here's an outline from my Penguicon 2013 panel "Seltzer CRM."
Pages
Copyright © Edward L. Platt 2011–2024
