One more time, with feeling! Toward reproducible computational science
My scientific education was committed at the hands of physicists. And though I've moved on from academic physics, I've taken bits of it with me. In MIT's infamous Junior Lab, all students were assigned lab notebooks, which we used to document our progress reproducing significant experiments in modern physics. It was hard. I made a lot of mistakes. But my professors told me that instead of erasing the mistakes, I should strike them out with a single line, leaving them forever legible. Because mistakes are part of science (or any other human endeavor). So when mistakes happen, the important thing is to understand and document them. I still have my notebooks, and I can look back and see exactly what I did in those experiments, mistakes and all. And that's the point. You can go back and recreate exactly what I did, avoid the mistakes I caught, and identify any I might have missed. Ideally, science is supposed to be reproducible. In current practice though, most research is never replicated, and when it is, the results are very often not reproducible. I'm particularly concerned with reproducibility in the emerging field of computational social science, which relies so heavily on software. Because as everyone knows, software kind of sucks. So here are a few of the tricks I've been using as a researcher to try to make my work a little more reproducible.
Databases
When I'm doing anything complicated with large amounts of data, I often like to use a database. Databases are great at searching and sorting through large amounts of data quickly and making the best use of the available hardware, far better than anything I could write myself in most cases. They've also been thoroughly tested. It used to be that relational databases were the only option. Relational databases allow you to link different types of data using a query language (usually SQL) to create complicated queries. A query might translate to something like "show me every movie in which Kevin Bacon does not appear, but an actor who has appeared in another movie with Kevin Bacon does." A lot of the work is done by the database. What's more, most relational databases guarantee a set of properties called ACID. Generally speaking, ACID means that even if you're accessing a database from several threads or processes, it won't (for example) change the data halfway through a query.
In recent years, NoSQL databases (key-value stores, document stores, etc.) have become a popular alternative to relational databases. They're simple and fast, so it's easy to see why they're popular. But their simplicity means your code needs to do more of the work, and that means you have more to test, debug, and document. And the performance is usually achieved by dropping some of the ACID requirements, meaning that in some cases data might change in the middle of a calculation or just plain disappear. That's fine if you're writing a search engine for cat gifs, but not if you're trying to do verifiably correct and reproducible calculations. And the more data you're working with, the more likely one of these problems is to pop up. So when I use a database for scientific work, I currently prefer to stick with relational databases.
Unit tests
Some bugs are harder to find than others. If you have a syntax error, your compiler or interpreter will tell you right away. But if you have a logic error, like a plus where you meant to put a minus, your program will run fine, it'll just give you the wrong output. This is particularly dangerous in research, where by definition you don't know what the output should be. So how do you check for these kinds of errors? One option is to look at the output and see if it makes sense. But this approach opens the door to confirmation bias. You'll only catch the bugs that make the output look less like what you expect. Any bugs that make the output look more like what you expect to see will go unnoticed.
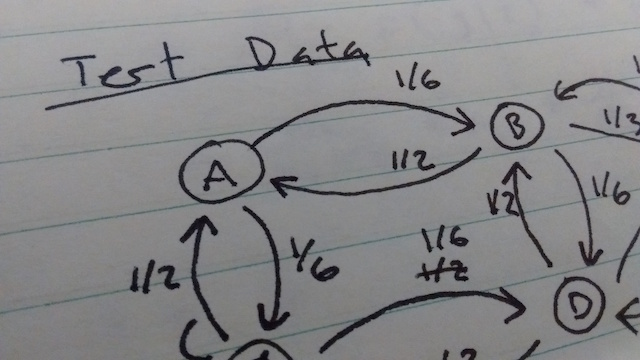
So what's a researcher to do? This is where unit tests come in. Unit tests are common in the world of software engineering, but they haven't caught on in scientific computing yet. The idea is to divide your code into small chunks, and test each part individually. The tests are programs themselves, so they're easy to re-run if you change your code. To do this in a research context, I like to compare the output of each chunk to a hand calculation. I start by creating a data set small enough to analyze by hand, but large enough to capture important features, and writing it down in my lab notebook. Then for each stage of my processing pipeline, I calculate what the input and output will be for that data set by hand and write that down in my lab notebook. Then I write unit tests to verify that my code gives the right output for the test data. It almost always doesn't the first time I run it, but more often than not it's a problem with my hand calculation. You can check out an example here. A nice side effect of doing unit tests is that it gives you confidence in your code, which means you can devote all of your attention to interpreting results, rather than second guessing your code.
Version control
Version control tools like git are becoming more common in scientific computing. On top of making it easy to roll back changes that break your code, they also make it possible to keep track exactly what the code looked like when an analysis was run. That makes it possible to check out an old version of code and re-run an analysis exactly. Now that's how you reproducible! One caveat here: in order to keep an accurate record of the code that was run, you have to make sure all changes have been committed and that the revision id is recorded somewhere.
Logging

Finally, logging the process of analysis scripts makes it a lot easier to know exactly what your code did, especially years after the fact. In order to help match my results with the version of code that produced them, I wrote a small logging helper script that automatically opens a standard python log in a directory based on the experiment name, timestamp, and current git hash. It also makes it easy to create output files in that directory. Using a script like this makes it easy to know when a script was run, exactly what version of the code it used, and what happened during the script execution.
As for the specific logging messages, there are a few things I always try to include. First, I always have a message for when the script starts and completes successfully. I also wrap all of my scripts in a try/except block and log any unhandled exceptions. I also like to log progress, so that if the script crashes, I can know where to look for the error and where to restart it. Logging progress also makes it easier to estimate how long a script will take to finish.
Using all of these techniques has definitely made my code easier to follow and retrace, but there's still so much more that we can do to make research truly open and reproducible. Has anyone reading this tried anything similar? Or are there things I've left out? I'd love to hear what other people are up to along these lines.
Return to Moderate Drinking is Still a Lie
Every few years, someone discovers that problem drinkers can return to moderate drinking—and they're always wrong. So when I saw an op-ed in the New York Times entitled "Cold Turkey Isn't the Only Route," I was disappointed, but not surprised. The op-ed, written by Gabrielle Glaser in support of her new book, has a simple message: for those who struggle to control their drinking, moderation is an alternative to abstinence. This claim is not new, and it's been disproven time and time again, often at the cost of human lives.
The first excitement over moderate drinking came after a 1962 case study by D.L. Davies. Of 93 patients treated for alcohol addiction, Davies found 7 who self-reported (with corroboration from family) drinking at most 3 pints (4 12 oz. drinks) of beer per day for at least 7 years after their treatment[1]. Although this sparked the first wave of claims that alcoholics could achieve moderate drinking, Davies' actual conclusion was that "the generally accepted view that no alcohol addict can ever again drink normally should be modified, although all patients should be advised to aim at total abstinence." Unfortunately, even that modest claim turned out to be based on bad data. A 1994 followup concluded that (surprise!) his patients had understated the severity of their drinking[2].
In the 1970s Mark and Linda Sobell picked up the torch. They devised an experimental technique to train alcoholics to drink moderately and tested it on 20 patients, concluding "some 'alcoholics' can acquire and maintain controlled drinking behavior over at least a 1-yr follow-up interval[3]." Based on those 20 patients, they wrote a book to teach their method to the general public[4]. In 1982, a team of scientists from UCLA did an independent review and follow-up with the Sobells' patients, finding very different outcomes:
Only one, who apparently had not experienced physical withdrawal symptoms, maintained a pattern of controlled drinking; eight continued to drink excessively—regularly or intermittently—despite repeated damaging consequences; six abandoned their efforts to engage in controlled drinking and became abstinent; four died from alcohol-related causes; and one, certified about a year after discharge from the research project as gravely disabled because of drinking, was missing[5].
In 1984, a Federal panel investigated the Sobell's for fraud. The panel found ambiguous language, errors, incorrect statements, and that the Sobells had "overstated their success," but attributed these discrepancies to carelessness rather than deliberate fraud[6].
The 1970s also saw an oft-cited study from the RAND Corporation, reporting that moderate drinking didn't predict relapse in patients previously treated for alcohol problems[7]. But that study only followed patients for six months. A four-year follow-up by the same researchers found that many of the original study's "moderate drinkers" had relapsed[8][9].
In Wednesday's op-ed, Glaser mentions a program called Moderation Management (MM) and reports meeting many women who have used it to change their drinking habits, but she doesn't go into MM's history. In 1994, on the heels of the Sobells' study and the first RAND report, a woman named Audrey Kishline came across the research on moderate drinking. She believed she was a problem-drinker, but not a chronic drinker, and embraced moderate drinking as her goal. Then, under the guidance of the Sobells, and contemporary moderate-drinking proponents Jeffrey Schaler, Stanton Peele, and Herbert Fingarette, she founded Moderation Management. She wrote a book, analogous to AA's "big book," to help other problem-drinkers like herself find an alternative to abstinence[10]. MM continued to grow and gain members over the next 6 years.
Then, on March 25, 2000, Kishline crashed her truck into oncoming traffic on Interstate-90, killing a 38-year-old man and his 12-year-old daughter. At the time, Kishline had been on a two-day vodka bender. She later admitted to NBC that while running Moderation Management, she'd been breaking her own rules, drinking at least 3 or 4 drinks a day, every single day, and sometimes binging on 7 or 8[10]. In her interview, she said she still believes problem-drinkers can achieve moderation as long as they're not truly alcoholic, but when asked where that line is, she replied "Nobody knows."
Kishline's experiment failed, and the small-scale, short-term, self-reporting studies claiming to show a return to moderate drinking have all fallen apart under scrutiny. The longest, largest study of the behavior of problem-drinkers has been by Harvard's George Vaillant, who studied over 600 subjects from the 1930s to present day. His conclusion: "Training alcohol-dependent individuals to achieve stable return to controlled drinking is a mirage.[9]"
In Glaser's defense, she does qualify her claims, saying "This approach isn’t for severely dependent drinkers, for whom abstinence might be best." But (almost) no one suggests abstinence unless a drinker is already having problems. If you want to drink less, try drinking less. If that works, you don't need a book, if it doesn't, there's probably no book that can help you. Glaser's book follows the path laid out by the Sobells, Kishline, Schaler, Fingarette, and Peele: helping no one, and exploiting the hopes and denial of the chronically mentally ill.
If you'd like a credible source of information on alcoholism, I highly recommend Alcoholism: The Facts by Ann M. Manzardo et al. and The Natural History of Alcoholism Revisited by George E. Vaillant. For a more personal account, Drinking: A Love Story by the late Caroline Knapp is honest and brilliant. Let's finally put the myth of return to moderate drinking to rest.
[1] D.L. Davies. "Normal Drinking in Recovered Alcohol Addicts." Quarterly Journal of Studies on Alcohol 23 (1962): 94-104.
[2] G. Edwards. "D.L. Davies and 'Normal drinking in recovered alcohol addicts': the genesis of a paper" Drug and Alcohol Dependence 35.3 (1994): 249-259.
[3] M. Sobell, and L. Sobell. "Alcoholics Treated by Individualized Behavior Therapy: One Year Treatment Outcome." Behavior Research and Therapy 11 (1973):599-618.
[4] M. Sobel, and L. Sobell. Behavioral Treatment of Alcohol Problems: individualized therapy and controlled drinking. Springer, 1978.
[5] M.L. Pendery, I.M. Maltzman, and L.J. West. "Controlled Drinking by Alcoholics? New Findings and a Reevaluation of a Major Affirmative Study" Science 217(1982):169-175.
[6] P.M. Boffey. "Panel Finds No Fraud by Alcohol Researchers." New York Times. September 11, 1984.
[7] D.J. Armor, H.B. Braiker, and J.M. Polich. Alcoholism and treatment. Rand, 1976.
[8] J.M. Polich, D.J. Armor, and H.B. Braiker. The Course of Alcoholism: Four Years After Treatment. Rand, 1980.
[9] G.E. Vaillant. The Natural History of Alcoholism Revisited. Harvard University Press, 1995.
[10] A. Kishline. Moderate Drinking: The Moderation Management Guide for People Who Want to Reduce Their Drinking. Crown Publishing Group, 1994.
[11] D. Murphy. "Road to Recovery." Dateline. NBC. Sept. 1, 2006.
Copyright © Edward L. Platt 2011–2024
